Making API calls
About this guide
Use this guide if you want to use DigitalNZ’s API to search Turnbull Library and National Library digital collections. Building your own API requests to search the collections lets you be very specific, and also gather a lot of information at once, instead of going through pages of results yourself. We’re currently developing more guides to using the DigitalNZ API – keep an eye out.
Want to access and use more Library data?
Check our open data section for many different data sets – soon, you will be able to access the full set of Turnbull metadata there. On Tiaki, you can download individual EAD and EAC-CPF records directly.
Preliminary steps
This hypothetical research question seeks cartoons on rugby from 2011. Once you have completed this guide using the example, you should have developed the skills to formulate your own calls to meet your own research needs.
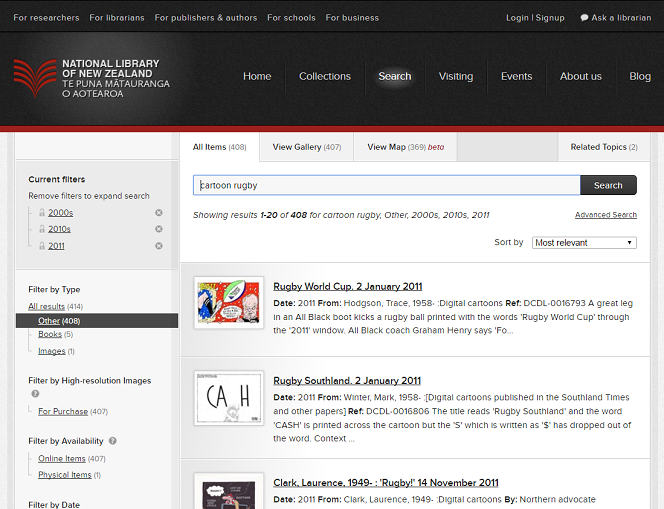
Before using the API, you should do a quick search using the National Library website. This enables you to find out if there are enough cartoons on rugby from 2011 to make using the API worthwhile.
Search for cartoon rugby (no quotes), then filter by other, then by 2011
You should get 408 results, of which 407 are online items
You now know that it will be worthwhile to use the API to pull metadata on this number of records.
Step 1: Generate an API key
Begin by going to DigitalNZ, and make an account by clicking the Signup link at the top right. Your personal API key is the long string of about 20 numbers and letters, ready for you to copy and paste where you need it. You can always log back into DigitalNZ if you need to find your API key again.
You can think of this process as similar to registering for a library account. Your ‘key’ is a unique way of identifying yourself and you should be sure to keep it private and not share it with anyone else.
Step 2: Read the information provided by DigitalNZ
The DigitalNZ website contains a lot of information on using their API.
Read Getting started, especially the first point about what data is available
You’ll find more help and specific references in their developers section
See how others have used the API in the showcase
Once you know your way around the API, check out the Metadata Dictionary
Step 3: Building a basic API string
An API string is a line of text that you can enter into the URL bar in your web browser (such as Chrome or Firefox). You can think of the string as a very precise command telling the API exactly what information you are looking for.
However, unlike when you ask a real-life librarian, the computer needs you to be very, very precise. So be aware, if you make any spelling mistakes or typos, it won't work. It is also case sensitive (watch-out for caps lock!). If you are copying and pasting from MSWord, you also need to be careful that symbols are used precisely, for example, “ is not the same as ".
Let’s get started with a basic call. It could look like this:
This string can be broken down into parts.
String part | What it does |
|---|---|
| This tells you that you are using DNZ’s API in version 3, and that you are asking for records. |
| This is the format in which you want the results returned. You could also ask for ‘json’ (you may need a json viewing plug-in for your browser). You can try swapping xml for json in your search string to see how each looks. The question mark starts the query. |
| This is where you enter your API key (your password). Where you see
here, you should enter your own 20 character key. |
| This is where you tell the API that you are looking for records containing the word ‘rugby’. |
| This is where you tell the API that you are looking for records in the collection of the New Zealand Cartoon Archive. You could also type TAPUHI if you wanted to search ATL’s collection. |
| This is where you tell the API to only show records from 2011. |
| This is where you tell the API what information you want. |
Be aware that depending on the program you are using hyperlinks can break in the process of copying and pasting. This does not always happen, but you may have to enter the string by hand.
Enter the whole string into your browser's address bar:
Press enter and you will get some results. It should look like this:
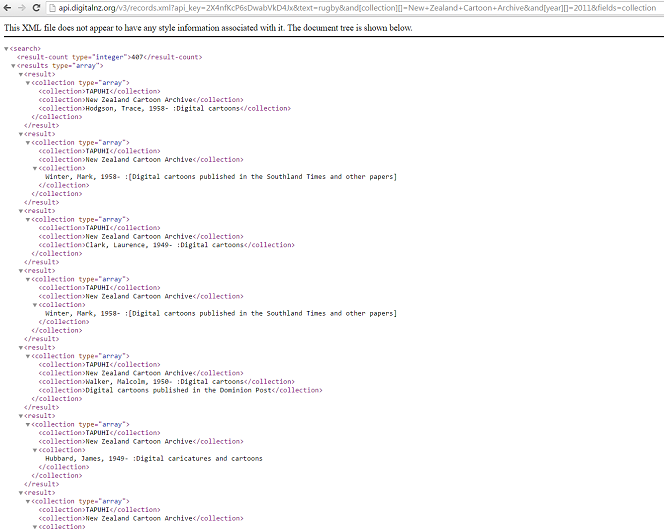
The first thing you will see is that the result-count is 407. This is the same number of cartoons on rugby from 2011 (in the online format) that the National Library’s website gave you. This means that your string worked!
Step 4: Improving your API string
Take a moment to have a look at your results. You should see two things: Firstly, even though it says you have 407 results, you can only see 20 different cartoons. Secondly, you are not getting very much information about each cartoon.
To fix this, you need to add one more piece of information to your search string and you also need to change one piece of information:
String part | What it does |
|---|---|
| This is where you tell the API how many records you want to see on one page. Currently, DNZ have the default set at 20 and the most they will give you is 100, which is what you are asking for here. |
| This is where you tell the API to return all the publically available information on these records. |
Add &per_page=100 to the end of your string
Replace fields=collection with fields=verbose
Enter your new string into the URL. It should look like this:
You will now see the first page of 100 records. But you want all 407 records. This means you need to make several API calls. The API results are always returned in the same order. To get all of the results, you therefore add the different page numbers to the string.
Take the 407 results and divide it by the per page value of 100: you need to make five different calls. You need to add one more piece of information:
String part | What it does |
|---|---|
| This is where you tell the API which page of information to return. Without this information, it will return the first page by default. |
Add the different page numbers to the end of your string. The first one should look like this:
And the last one should look like this:
You are now ready to go with API strings that will return all the available metadata on all 407 records.
Step 5: Making a specific request with your API string
When you use the verbose request you will receive a lot of information. It is likely that this is more information than you really want. To fix this, you can ask the API for a more specific set of information.
Look at the information you returned in step four. The field names are given < inside-brackets-like-this > . The metadata unique to each record stands out in black.
Because the information is provided in a nested form (like folders inside folders), you may not be able to ask for one piece of information without also getting others pieces. For instance, in the screen shot below, you could ask the API for the field, but that would return several pieces of information, telling you the record was in: TAPUHI, Drawings and Prints Archive, New Zealand Cartoon Archive and Hodgson, Trace.
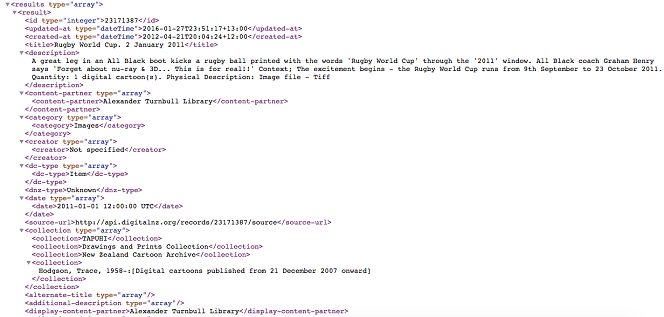
Try to identify what information will be useful to you. The xml format may take some getting used to, so if you find it easier you can go back to a Tiaki record to see what information you would like.
Requesting the fields you want can be a little tricky, because the name given to the ‘fields’ in Tiaki is not the same as the name of the fields in the API. The following list may help you decide what you might like to ask for:
DNZ field | Tiaki field |
|---|---|
title | Title (for cartoons, this field includes title, cartoonist and date). |
description | Scope and Contents. |
dc-identifier | This includes the ATL collection number. It also includes other information that you cannot see in Tiaki. |
origin url | This is the stable Tiaki URL. This links to the webpage for each item. |
large thumbnail image | This information is not available via Tiaki, but it is potentially very useful for later research, when you can insert image thumbnails into your tables automatically. |
authority headings | This includes subject, name and place authorities. It also includes ‘collection root’: where you can find the name of the cartoonist if it’s not in the title. |
ID (this is assigned by DNZ) | This number has no equivalent in Tiaki, but will be useful if you want to do more advanced work with your metadata. |
The fields that you see returned with your verbose string may need to change slightly when you want to individually request them. Specifically, anything with a hyphen needs to change to an underscore: dc-identifier needs to go into the string as dc_identifier
You can now choose to ask the API for a limited number of fields so that you don’t get a lot more information than you want. For instance, you could ask for fields=description, or you can ask for a few things at once, like fields=description,id,title
You should ask for the following fields: id, origin url, title, description, collection, dc identifier, large thumbnail and authorities. Your first string needs to look like this:
As in step 4, you will need to repeat that call 5 times to return all of the records (change the end to page=2 etc).
You have now created API strings that will return the information you want about all 407 records in which you are interested.
In the next guide you will learn how to export your data into OpenRefine2.6, a tool for working with large, irregular datasets and cleaning or transforming it from one format into another.
Acknowledgements
This guide was written by Dr. Melinda Johnston and checked by Flora Feltham. Further help from Amy Watling, Jay Buzenberg and Reuben Schrader.